Results may vary in legal research databases
HOW ALGORITHMS WORK
I originally noticed that when I compared a single search in more than one database, the results varied widely. I used these one-off comparisons to illustrate to my students that algorithms differ, and that over-reliance on keyword searching might not be the best search strategy.
I also noticed that if I ran the same search a year later, the results still varied widely and different cases turned up in the results. One would expect new cases to show up, but older cases turned up as well. Algorithms are fluid, not static. Since one-off searches do not prove that much, I thought it would be interesting to run the experiment on a larger scale and see what happened. I crafted 50 different searches and had law student research assistants look at the top 10 results.
How unique are the search results? When you search in most databases, there is no way to determine what documents are actually in the database and which documents are excluded. In legal databases, jurisdictional and coverage limits allow you to know exactly which set of documents is being searched. If one searches a database of reported cases in the 6th U.S. Circuit Court of Appeals at Cincinnati, every database provider has the same documents, plus or minus a few cases from 1925 to 1933.
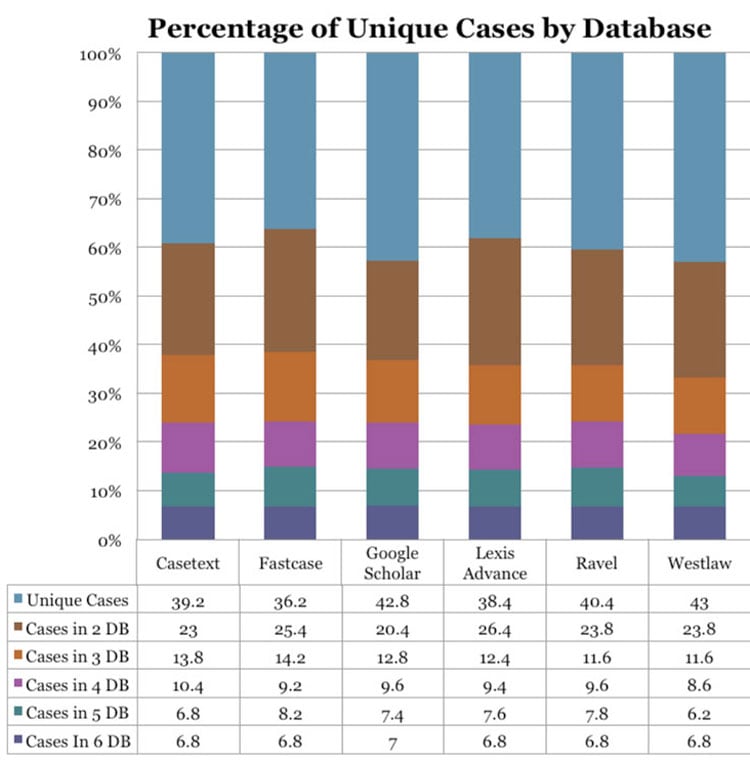
Computer scientists would expect some variability in search algorithms, even if lawyers do not have the same expectations. Here, however, each vendor’s group working on the research algorithm has an identical goal: to translate the words describing legal concepts into relevant documents. One of the hypotheses of the study was that, as the number of searches expanded, the overall results returned by the algorithms from each database provider would be similar. The top 10 cases ought to be somewhat similar. That hypothesis did not turn out to be true, as shown in the chart above, “Percentage of Unique Cases by Database.”
The blue bar at the top shows the percentage of unique cases in each database. An average of 40 percent of the cases in the top 10 results are unique to one database. Nearly 25 percent of the cases only show up in two of the databases. The numbers drop quickly after that, and only 7 percent of the cases show up in five or six of the databases. When the comparison was limited to the two oldest database providers, Lexis Advance and Westlaw, there was only 28 percent overlap. That means that 72 percent of the top 10 cases are unique to each provider.
Starting with a keyword search is just one way to frame a research problem. Legal research is a process that has always required redundancy in searching. The rise of algorithms has not changed that. Researchers need to use multiple searches, of multiple types, in multiple resources. But if a researcher starts with a keyword search, each legal database provider is going to offer a different set of results and, therefore, a different frame for the next steps in the research process. This means that where you start your search matters.
RESEARCHERS WANT RELEVANT RESULTS
The searches for the study each incorporated known legal concepts. The searches were the kind that a lawyer with any expertise in the area could easily translate into a recognizable legal issue. Here is an example of the kind of search used in the study: criminal sentence enhancement findings by jury required (the search was limited to the reported cases in the 6th Circuit).
Lawyers with subject expertise would know that the search is about the constitutionality of increasing the penalty for a crime when the jury did not make a specific finding about the facts that enhanced the penalty. This background statement was given to the RA who ran the search in each of the six legal databases and read the resulting top 10 cases from each database to see whether the cases were relevant or not. This translation—from the human putting in keywords that represent a legal problem to the documents the human-created algorithm determines are responsive—is at the heart of all human/computer legal research interaction. The study tested how the humans creating the algorithms tried to implement that translation. The decision to limit the results to the top 10 was based in part on the assumption that returning relevant results at the top is the goal of every team creating a legal research algorithm, a view that database provider ads and FAQs support. And modern researchers tend to look at the top results and then move on.
The RAs were given a framework for relevance determinations based on the background statement and on explicit instructions for determining relevance: A case was relevant, in our example, if it discussed situations where juries did (or did not) make sufficient factual determinations to support an enhancement of the sentence in a criminal case. If a case was in any way related to determining the contours of the role of the jury, it would be marked as “would definitely be saved for further review” or “would probably be saved for further review.” This study does not say that the cases that are “relevant” are necessarily the best cases, just that they are cases playing some “cognitive role in the structuring of a legal argument,” as Stuart Sutton put it in The Role of Attorney Mental Models of Law in Case Relevance Determinations: An Exploratory Analysis. This is a broad and subjective view of relevance that should resonate with all attorneys who have created mental models of an area of the law.
Clarification
Print and initial online versions of “Results May Vary,” March, should have noted that the data cited is from a 2015 study by author Susan Nevelow Mart. Algorithms and their results are continually changing, and each of the legal database providers in that study has changed their algorithms since the data was collected.
Susan Nevelow Mart is an associate professor and the director of the law library at the University of Colorado Law School in Boulder. This article was published in the March 2018 issue of the


